
티스토리 뷰
spin github: https://github.com/nkolot/SPIN
spin 깃헙을 보면 demo.py라고 자기들의 mesh output을 image에 projection 시켜서 visualize하는 코드가 있다. mesh를 여전히 3D처럼 보이게 하면서 이미지에 겹쳐보이게 하는 코드로, 3D mesh estimation 연구들에서는 당연히 필요하고 자주 쓰는 기능이다. 나는 내가 짜기 귀찮으니(+어렵) 얘네 것을 갖다 썼다.
그런데 얘네가 pyrender를 통해 mesh를 projection 시키기 위해 camera node를 만들고 camera translation이라는 것을 이 node에 input으로 주는데, 이 부분이 좀 이해가 안 갔다.

pred_camera는 얘네 model의 output 중 하나로 weak perspective camera parameter (s, tx, ty)를 의미한다. 스크린샷의 첫 번째 줄 코드는 (s, tx, ty)를 (tx, ty, tz)로 바꾸는 코드이다. 여기서 camera translation (tx, ty, tz)는 github.com/nkolot/SPIN/blob/21a148d29ea99627bd24cd51997d1484986c196e/utils/geometry.py#L83를 참고하면, mesh vertices들의 camera-centered coordinate system 상에서의 translation vector를 말하는 듯하다. 아무튼 내가 이해가 안 갔던 것은 위 스크린샷의 첫 번째 줄 코드인데, s가 대체 무엇인지 이해가 안 갔다. 위의 스크린샷과 동일한 코드가 여기도 나오는데, 나는 여기의 코드를 바탕으로 (s,tx,ty)의 의미를 추적할 수 있었다.

pyrender를 쓰는 코드를 보면 그 라이브러리만의 coordiante system때문에 더 헷갈리게 될 것이다. 아무튼 첫번 째 줄 코드의 의미(혹은 바로 위 스크린샷의 주석의 의미)를 수식으로 써보면 다음과 같다.
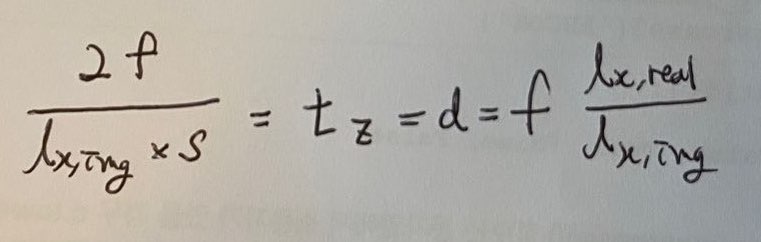
lx,img(pixel)가 constants.IMG_RES (=bounding box의 x크기) 이고, lx,real이 lx,img의 실제 3D 공간상에서의 크기(mm)이다. f는 constants.FOCAL_LENGTH인데, 이것은 사실 mm단위의 focal length그대로는 아니고, focal length를 per-pixel distance factor로 나눈 것이다. 당연히 그도 그럴 것이 tz(=d)의 단위는 mm인데 constants.IMG_RES 는 pixel이므로 per-pixel distance factor가 분모에 곱해져서 pixel이 소거되야 한다. d = f * (lx,real/lx,img)가 어떻게 derive되는지는 이 포스트를 참고하면 된다. (저 포스트에서 alpha가 여기 f이다.) 아무튼 다시 수식으로 돌아오면, 결국 s는 다음과 같다.
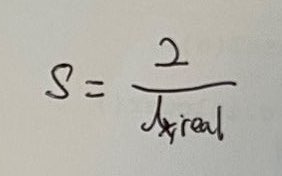
결국 s는 2를 bounding box의 x크기 (spin코드에서는 constants.IMG_RES=224로 고정되어있음)의 실제 3D 공간상에서의 크기(mm)로 나눈 값이며, 역수,상수 떼고 보면 결국 spin의 model이 estimate 하는 s는 224라는 주어진 bounding box의 실제 3D 공간상에서의 크기(mm)이다. 여기서 계속 말하는 bounding box는 실제 이미지에서 detect된 bounding box가 아니라, detect된 bounding box로 crop한 224x224로 resize한 crop image를 말하며, bounding box의 x크기 또한 그 crop image의 x 사이즈인 224를 말한다.
나는 얘네 코드를 그대로 갖다 쓰려 했기 때문에 정확히 위에서 규명한 (s, tx, ty)를 구할 필요가 있었다. 여기서부터는 개인 연구용 코드에 대한 설명인데, self.cam_param[0,2] 가 어떻게 위에서 규명한 s와 정확히 같은 의미를 가지는 지, 그래서 이 코드를 통해 구한 내 (s, tx, ty)를 그대로 쟤네 코드에 써도 되는 지에 대한 설명이다.

여기서 pose3d는 camera coordinate 상의 root-joint relative joint들의 3D coordinates (mm)들이고, output은 bounding box로 crop된 이미지 (224x224, 즉 spin코드에서와 동일) 상에서의 joint들의 2D coordinates (pixel)이 되야 한다. tx,ty부분인 self.cam_param[0, :2]는 됐고, self.cam_param[0,2]는 무슨 의미를 가지는가. 미세하게 조정된 root-joint relative joint들의 3D coordinates를 둘러싸는 실제 3D 공간상에서의 bounding box의 x,y크기를 -1~1 사이로 scaling하는 값이다. 그래야 *112+112 했을 때 ouput이 최종적으로 0~224 사이의 값을 가지기 때문이다. 방금 두 문장이 의미하는 것은 결국 output*self.cam_param[0,2] 부분의 코드가 곧 lx,real의 크기를 가지는 3D coordinates를 둘러싸는 실제 3D 공간상에서의 bounding box의 x에 2/lx,real를 곱하는 것과 같다는 말이다. 구간이 -1~1로 fitting되는 이유는 output과 error를 계산하는 2d pose의 구간이 0~224이기 때문도 있지만, 애초에 pose3d의 joint coordinates들이 root joint (0,0,0)을 기준으로 대략 -1000~1000 사이의 값을 가지기 때문도 있을 것 같다. 이렇게 해서 self.cam_param[0,2]와 spin코드의 s가 동일한 의미를 가짐을 규명했다.
spin docker사용해서 mesh를 image에 projection 시키기
밑의 내용은 순전히 내 연구용이며, 나중에 까먹었을 때의 대비용이다.
sudo docker restart spin
sudo docker attach spin
cd /home/SPIN
python3 demo.py --checkpoint=data/model_checkpoint.pt --img=examples/im1010.jpg --openpose=examples/im1010_openpose.json
내가 demo.py에 추가한 코드 보고 사용할 mesh result와 image path만 고치면 된다. python3 demo.py ~부분에서 arguement들은 의미없고 demo.py의 기존 코드를 안 바꿨기 때문에 써줘야 할 뿐이다.
optimize한 mesh result 결과는 camera_fitting, camera_fitting_frei 브랜치의 코드를 돌리면 됨.

docker 사용법 기초
https://nicewoong.github.io/development/2017/10/09/basic-usage-for-docker/
docker 파일 전송
'Research (연구 관련)' 카테고리의 다른 글
| Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image (5) | 2020.07.01 |
|---|---|
| detectron2 install (0) | 2020.06.23 |
| random walk & markov chain (0) | 2020.05.22 |
| densepose parts definition (0) | 2020.05.21 |
| smplify-x install (3) | 2020.04.17 |
- Total
- Today
- Yesterday
- focal length
- 헬스
- 컴퓨터비젼
- Docker
- Virtual Camera
- part segmentation
- Pose2Mesh
- nohup
- 문경식
- 2d pose
- 머신러닝
- spin
- Machine Learning
- Interview
- VAE
- 인터뷰
- nerf
- camera coordinate
- 에디톨로지
- Generative model
- pytorch
- 피트니스
- deep learning
- pyrender
- demo
- densepose
- world coordinate
- Transformation
- 컴퓨터비전
- 비전
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |