
 Human3.6M (h36m) original data analysis
Human3.6M (h36m) original data analysis
Human3.6M에 part segmentation annotation이 있었다. 없는 줄 알고 예전에 densepose돌려서 얻었었는데... 퀄리티가 더 좋은지는 모르겠으나 괜찮아 보인다. 다만 README(로그인 안되어있으면 안 열릴수도)에도 part label에 대한 설명이 없어서 직접 분석함. 하는 김에 원본 데이터와 경식이형 parsing 데이터 관계도 정리함. 원본 데이터와 경식이형 parsing 데이터 명칭 관계 cam_name_mapper = {'01': '54138969', '02': '55011271', '03': '58860488', '04': '60457274'} action_name_mapper = { '01': {'act_02_subact_01': 'Directions 1', '..
 좌표계 변환, camera parameter
좌표계 변환, camera parameter
경식이형의 코드와 parsing된 데이터셋 annotation json들을 보면 camera extrinsic parameter인 R,t가 다음과 같이 정의됨을 볼 수 있다. def world2cam(world_coord, R, t): cam_coord = np.dot(R, world_coord.transpose(1,0)).transpose(1,0) + t.reshape(1,3) return cam_coord 위의 코드를 해석하자면, world coordinate system에 정의된 대상(주로 우리는 keypoint다, Xw라고 하겠다)의 좌표를 camera coordinate system의 좌(Xc)로 바꾸기 위해, Xc = RXw + t를 하는 것이다. 그런데 사실 이 R,t라는 변수가 물리적으로 ..
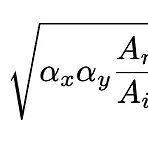 Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
2019 ICCV 논문으로 연구실 선배인 경식이형의 논문이다. 이 포스트의 목적은 이 논문의 모듈 중 하나인 'RootNet'에 대해서, 그 중에서도 논문 자체의 contribution보다는, focal length, camera-object distance (depth), per-pixel distance factor에 대해 다룬 내용을 이해하는 것이다. RootNet의 output은 human root joint의 coordinate인 (x,y,Z)이다. x,y는 img coordinate이고, Z는 camera-centered coordinate system 상의 coordiante으로 root joint의 depth다. inference time 때 x,y는 Z를 구한 후에 Z값과 미리 가정한 f..
- Total
- Today
- Yesterday
- VAE
- 머신러닝
- 컴퓨터비전
- 2d pose
- Virtual Camera
- camera coordinate
- nohup
- 컴퓨터비젼
- 헬스
- Pose2Mesh
- Docker
- part segmentation
- Machine Learning
- Generative model
- 비전
- 에디톨로지
- deep learning
- 피트니스
- pyrender
- Transformation
- demo
- pytorch
- spin
- 인터뷰
- focal length
- densepose
- nerf
- world coordinate
- 문경식
- Interview
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |