
티스토리 뷰
What is KV caching?
KV caching is specifically related to the auto-regressive approach of a transformer decoder. In a transformer decoder, it attends to the past and current tokens, but not to future tokens. At each time step, the transformer repeatedly calculates the attention scores between the query and the key, and computes the values by multiplying the scores with the previously computed values to perform the weighted sum. Instead of repeatedly loading the same keys and performing the same computations (attention score calculation and value multiplication), the keys and values can be cached and reused. This significantly speeds up (x2~x4) the auto-regressive process of the transformer decoder.

https://medium.com/@joaolages/kv-caching-explained-276520203249
How does GPT-2 relate to self-supervised learning? What is a language modeling?
GPT-2 is trained in a self-supervised learning using the language modeling objective, which is to predict a next token given previous tokens (previous context), not requiring manually labeled data.
What's the difference between BERT and GPT-2? What is the trade-off?
BERT is a transformer encoder-only model and GPT-2 is a transformer decoder-only model. BERT can attend to future tokens but GPT-2 cannot. The trade-off is a generation capability versus overall context understanding in both sides (past and future).
Losing auto-regression is considered a disadvantage because auto-regression is critical for text generation tasks, where the model needs to produce coherent sequences one token at a time. Here’s why:
1. Sequential Dependency for Generation:
- Auto-regression models like GPT-2 predict the next token in a sequence by attending only to past tokens. This makes them inherently suitable for tasks that require generating sequences, such as language generation, storytelling, and translation.
- Without auto-regression, as in BERT, the model cannot generate coherent text sequentially because it considers the entire context at once and doesn't follow the natural order of sequence generation.
2. Applicability to Language Modeling:
- Autoregression ensures that the model adheres to the causal structure of language, where words are naturally ordered in time. This is fundamental for predicting the next word in a sequence, a key feature in many generative tasks.
- Non-autoregressive models like BERT can't perform this task effectively, as they use bidirectional attention to process entire sequences rather than predict the next token based on previous ones.
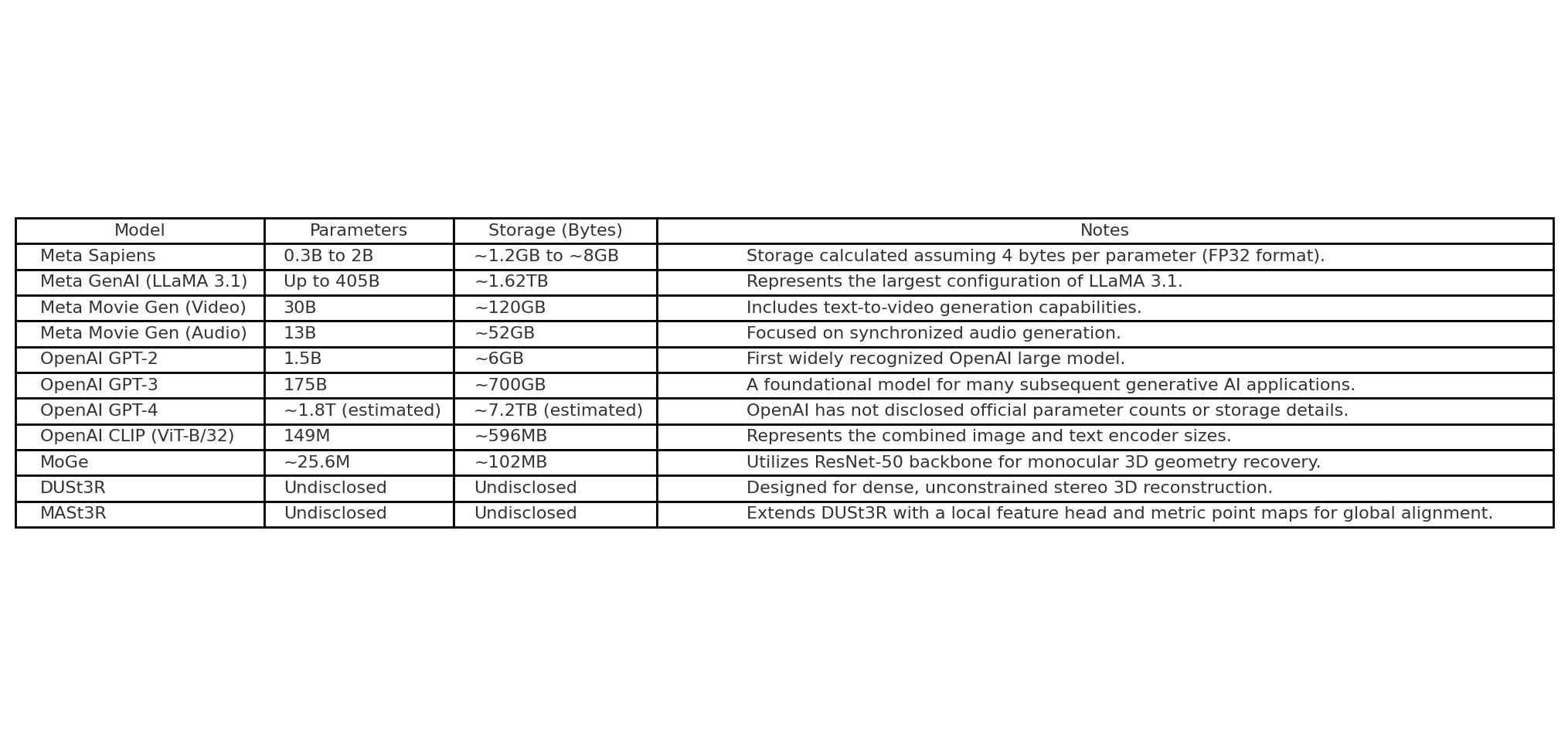
How large are the Large Models these days?
'Research (연구 관련)' 카테고리의 다른 글
| Dual Contouring (0) | 2025.01.17 |
|---|---|
| Generative AI - Diffusion / Lecture 1 (0) | 2024.11.27 |
| mmcv installation (0) | 2024.10.21 |
| Visualizing multiple people in the same world frame (0) | 2024.10.13 |
| Get depth from ARIA glasses (0) | 2024.10.08 |
- Total
- Today
- Yesterday
- focal length
- deep learning
- Pose2Mesh
- spin
- pytorch
- densepose
- Transformation
- nohup
- demo
- Generative model
- world coordinate
- 비전
- Docker
- nerf
- Machine Learning
- Virtual Camera
- VAE
- part segmentation
- 에디톨로지
- 헬스
- pyrender
- 컴퓨터비젼
- 문경식
- Interview
- camera coordinate
- 컴퓨터비전
- 머신러닝
- 인터뷰
- 피트니스
- 2d pose
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |